%20(1).jpg?width=300&name=Data%20lake%20-%20blog%20post%20header%20(2240%20%C3%97%20600%20px)%20(1).jpg)
“Big Data” has been a part of the collective vocabulary for some time now. However, there is a common misconception that a lot of data means “better” decisions. There are big challenges in the amount of data, mainly related to our ability to know and retrieve what is ‘relevant’ data for processing.
The fact is that data is most often decentralised, spread across folders and computers, with duplicates and versions everywhere. Retrieving and making use of earlier interpretations is a huge challenge, taking up too much time to be economical at scale. The same wireline log, for example, exists in so many LAS-files and it’s hard for the user to know that the one he is using is the correct one. However, all this data is also an asset, with a wealth of potential knowledge.
In this article we will look at what a Data Lake is, its importance in solving many of these challenges and how it can be integrated into your workflows.

What is a Data lake?
A common challenge in geoscience analytics work, and scientific analytics work in general, is that data is not readily available. In fact, it can take up to 80% of a scientist’s time to just get the data ready.
A Data Lake refers to a pool of data that is structured, organised and accessible at high speed. However, it is not really the data itself that is groundbreaking. A data lake is one more layer of abstraction, of the data. A higher level of contextualisation which is elevating the idea of metadata to the next level, allowing you to make queries to the data itself, not just the metadata. Every asset, together with its history of analysis, is made accessible in a very efficient manner.
Traditionally, data remains application specific, meaning it resides in folders for the specific task and the software it is processed. Utilising the data in other applications and software, perhaps years later, is therefore non-trivial. In fact, it can be a huge undertaking.
Data compartmentalised in such a way, makes it very difficult to use them in other workflows. It’s therefore immensely valuable if the work of cleaning and contextualising is already done before analysis begins. And it should only be done once!
Data Lake is not a storage solution
There are several ways of centralising data, but what you should look for is a solution that gives you complete control and overview of what’s available and its history.
You want a data storage solution that is:
- Well organised using meta-data
- Supports all data structures, units and types.
- Software neutral and non-proprietary
- Can be easily accessed using Application Program Interfaces (APIs).
- Secure, providing confidence that business sensitive data is for the organisation’s eyes only, while also be accessible to outside partners, should the organisation so choose.
To achieve this, we start with the Open Subsurface Data Universe, OSDU. OSDU is already being adopted by industry leaders within oil and gas, renewables, CCS, and mineral mining.
The OSDU Forum states the following steps to achieve their mission:
‘’Integrated Upstream’’: Making sure that the full spectrum of Upstream services (Exploration to Production) is enabled by the OSDU Data Platform.
‘’Realtime as the standard”: Making sure that any amount of real time data can be handled by the OSDU Data Platform and linked Edge facilities.
‘’Support for End-to-End services’’: Supporting the complete supply chain for existing (gas) and new Energy sources.
‘’Any mixture of Energy sources”: Enable OSDU platform readiness for adopting new data types and service in support new business domains.
https://osduforum.org/about-us/who-we-are/osdu-mission-vision/
However, using meta-data alone for indexing and contextualisation is insufficient when you want to scale modern collaborative and integrated workflows. For collaborative workflows considering posterity, you must be able to query the data itself, not only its meta-data. You need further contextualisation than what OSDU offers. This is not a weakness of OSDU. It is a feature which allows you greater flexibility in terms of what solution you are using. This is where the Data Lake resides. Between your software applications and your main data store.
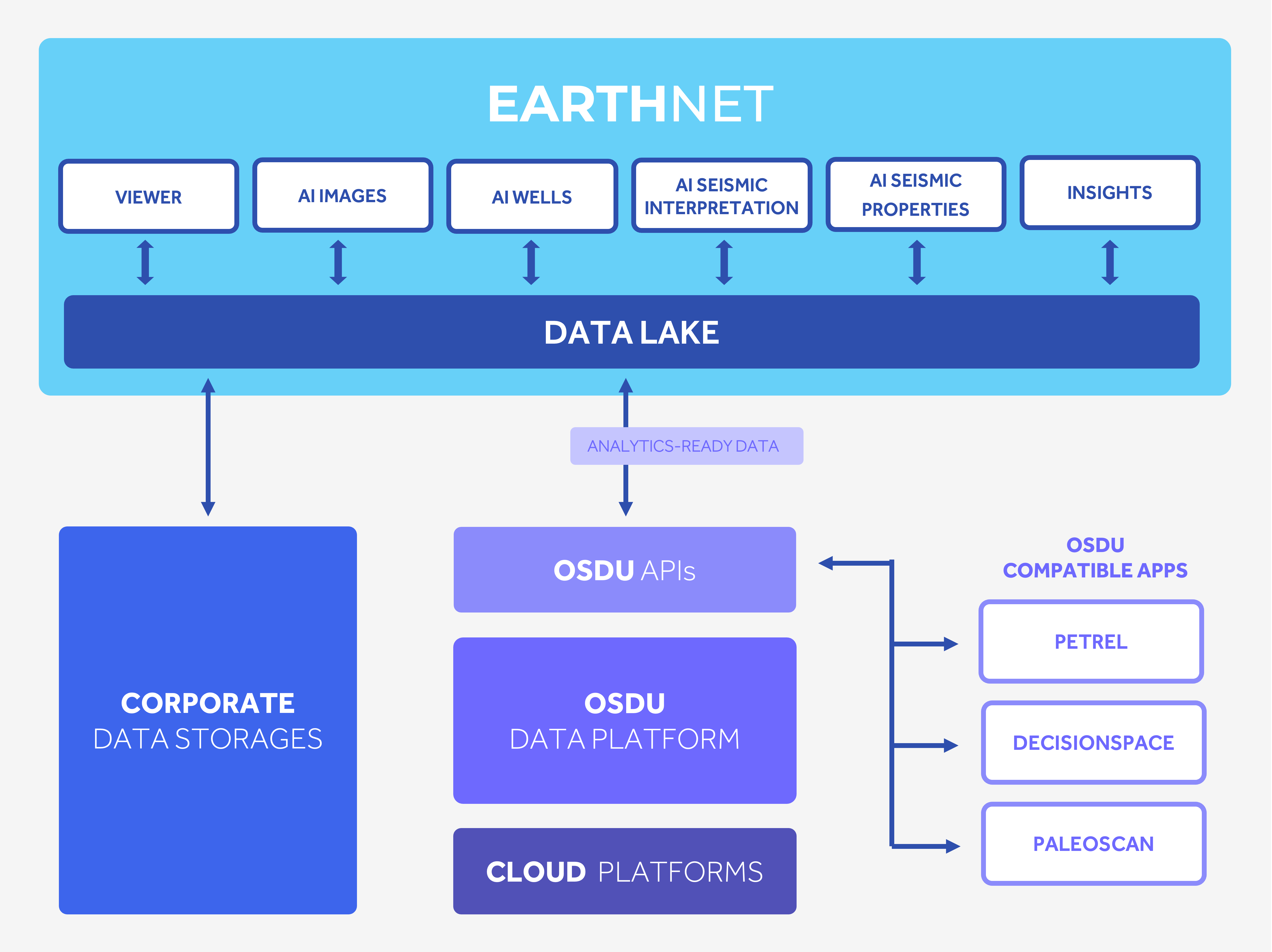
Next to the Data Universe, lies the Data Lake
A common misconception of the OSDU Data Platform is that all the data, all your testing, revisions, and results, must be transferred to OSDU. This is not the case. Only approved data need, and should, to be transferred. If not, you would simply be transferring the friction points of traditional methods to another platform. For an outsider to revisit data, perhaps years later, this is more than problematic.
Therefore, transferring all the data, from all existing user workstations, to the OSDU will be of no value. Users will face the same problem of having access to multiple definitions, revisions and rules while missing their context and history. The ‘latest’ document/schema in time is not necessarily the final interpretation. You might have finished your results on Thursday, but on Friday you were doing testing/confirmation.
To make order of this chaos you need another level of contextualisation. Data lake is a vault where the work happens, including detailed logs of what and when it was done. Your testing, your good ideas and bad ideas, and even your far-fetched experiments happen here.
Only when you have work that is final and approved internally, is it pushed to the OSDU. You now have information on what is final, but also have references to underpinning tests and experiments.
This is an integrated real-time system of your analytics platform. If someone else on your team pushes a new version affecting your current progress to OSDU, Data Lake facilitates notification and consolidation of it. Put simply,
Data Lake is a vault where the work is currently happening. When the work finishes, the approved version is pushed to OSDU.
Automatic ingestion of data
OSDU is the future of data storage, but the aforementioned reasons can make it painful to migrate to a new platform. Data Lake also functions as a data ingestion system for OSDU. Data Lake is connected to your company's existing hardware, consume and inspect the data QCs, tags them with updated metadata before pushing the data to the company’s OSDU.
This is important since, despite OSDU growing, it still lacks many data schema definitions. For example, wellties, allowing wells to be correctly projected in seismic surveys, has not yet been discussed in the OSDU forum. Users will need to repeat a welltie job, or start looking for existing ones in folders, software packages and projects with small chances to find a previously company approved welltie. The same holds for several other data types such as horizons, fault sticks and planes, etc.
A modern Data Lake covers this gap and you are provided with a comprehensive map of all your data. The user will not need to look for data, but can simply select the data of interest and the Data Lake will make queries to the connected databases, such as:
- OSDU
- Company’s proprietary databases
- Your company’s cloud
- On-premises storage
It’s not duplication of data. Data lake only stores the metadata with additional contextualisation information and data caching which enables it to provide high-speed connections to the company datastores. It is also able to hold intermediate data, like results of ongoing projects, before the final outcome of the project is pushed to OSDU.
All this data is now available to different software and disciplines simultaneously and is frictionless to revisit for outsiders in later studies. Now, faster turnaround on projects, with decisions based on a much larger quantity of quality data, is possible. And posterity for future studies is ensured.
Conclusion
Vital to all geoscience analytics workflows are proper access to your data.
Data Lake provides a higher degree of abstraction, contextualisation and caching allowing you instant access to the data you need. It supports all types of data, even image data, which can be accessed using open-source APIs.
It does not mean by definition putting all your data in the cloud, and the huge cost of server infrastructure that entails. Rather it is only data that is frequently used which needs to be transferred.
Your data is potentially the most valuable asset that you have, but this value is determined by how accessible it is for decision making. Data Lake allows your organisation to better grasp this asset, making it more accessible to your subject matter experts. It is, after all, the very fabric of all sub-surface analytics and interpretations.

