
Imagine trying to understand a story by only reading every hundredth word. That's the predicament of geologists when trying to decipher the mysteries beneath the Earth's surface. Rather than direct visuals, geoscientists rely on the echoes of sound, the paths of radiation, and the flow of electricity.
The direct glimpses we get are rare, mostly in the form of cuttings and core samples—our windows to the world deep below. Yet, for years, these precious rock samples have sat under-appreciated, gathering more dust than insights in storage rooms.
But what happens when you're faced with a staggering 800,000+ images to interpret and translate into structured data? To say the task is monumental is an understatement. Add in the challenge of syncing multiple experts, each with their own specialised skillset – one analysing rock samples, another decoding seismic data – and you see the complications. It's like assembling a jigsaw puzzle where each piece comes from a different set. Not only is this labor-intensive and time-consuming, but it's prone to errors and expensive.
Enter the era of digital transformation. Those closely watching trends in the geoscience sector would've caught wind of the increasing buzz around the digitisation of rock cuttings. The community is waking up to the immense potential these once-overlooked samples hold, especially when integrated into machine learning-based subsurface workflows. The promise? More accurate insights to guide decision-making.
By adopting AI to train this ground truth data, it’s possible to enrich the well interpretation with properties of many different types. This opens up multiple new opportunities for the energy sector, particularly where there is a lack of well penetration data. Once AI models have learnt the relationships between the integrated data, they can then predict as a function of the seismic data. This significant leap is supporting operators in activity that would never have been possible before, at a level and speed that was previously unimaginable.
In this article, we will look at the challenges with traditional workflows and the opportunities that arise from AI-driven composite workflows and data integration.

The challenges with traditional, siloed workflows
Every piece of data in geological analysis is like a piece of that puzzle, hinting at the bigger picture. Yet, instead of collaborating to put the puzzle together, experts have traditionally worked in isolation, layering their findings on top of one another. This fragmented approach involves individual scientists delving deep into their niche, drawing conclusions, and then passing the baton to the next expert.
Now, when you're juggling massive datasets, humans can only lean on educated assumptions. As a result, many analyses are not comprehensive; they’re based on selective, even if well-intentioned, choices rather than the entirety of the available data. This inevitably means the subsequent analysis might be based on an incomplete foundation.
To complicate things further, each category of data - and there are many - has its own specific process and requires unique expertise. Each piece of data gives a glimpse, just a fragment, of the subsurface story. These insights are consecutively relayed to the next specialist who's trying to stitch together a 3D model of what lies beneath.
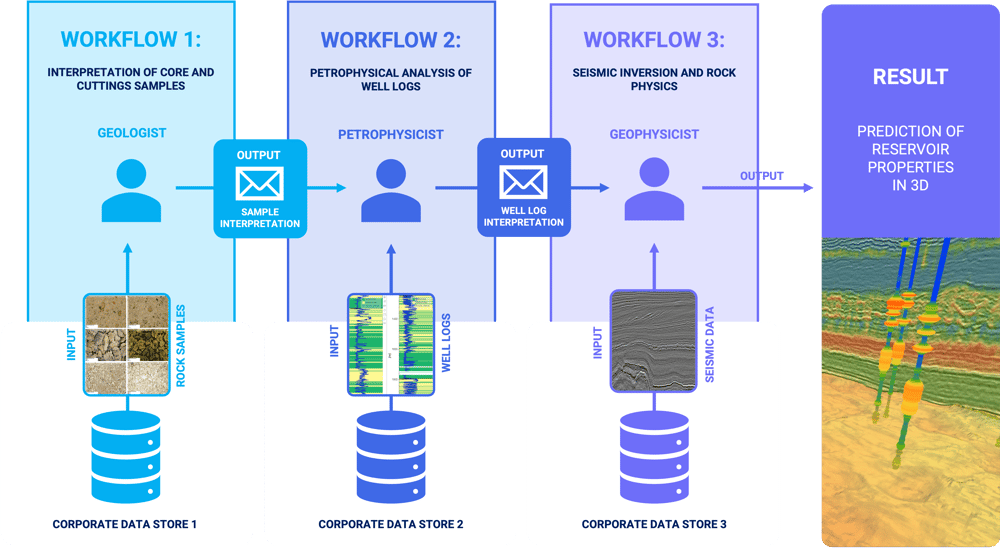
There are several challenges with this approach:
- There is no way of going back the chain of analysis.
- Results from one field is handed over to the next, combined with the results there.
- There is no integration between the different parts of the overall workflow.
While each expert possesses top-tier tools and a wealth of knowledge in their specific domain, the absence of a collaborative framework can lead to vital information getting misinterpreted or even lost in translation. In essence, this fragmented approach makes the task of subsurface analysis not only tedious and costly but also less effective.
The benefits of an AI-driven, integrated workflow
In a composite workflow, consisting of several machine learning models and several data types, we start with measured data of different types and end up with the key information we need to make decisions in three dimensions.
These 3D predictions offer valuable insights into the subsurface — from understanding hydrocarbon reservoir properties to evaluating CO2 storage capabilities or discerning geotechnical conditions essential for seabed installations, like wind turbines. Such data then form the cornerstone for pivotal business decisions. For instance, determining whether a CO2 storage site is sufficiently spacious, adequately porous, permeable, and if it possesses a robust seal to prevent CO2 from escaping back to the seabed.
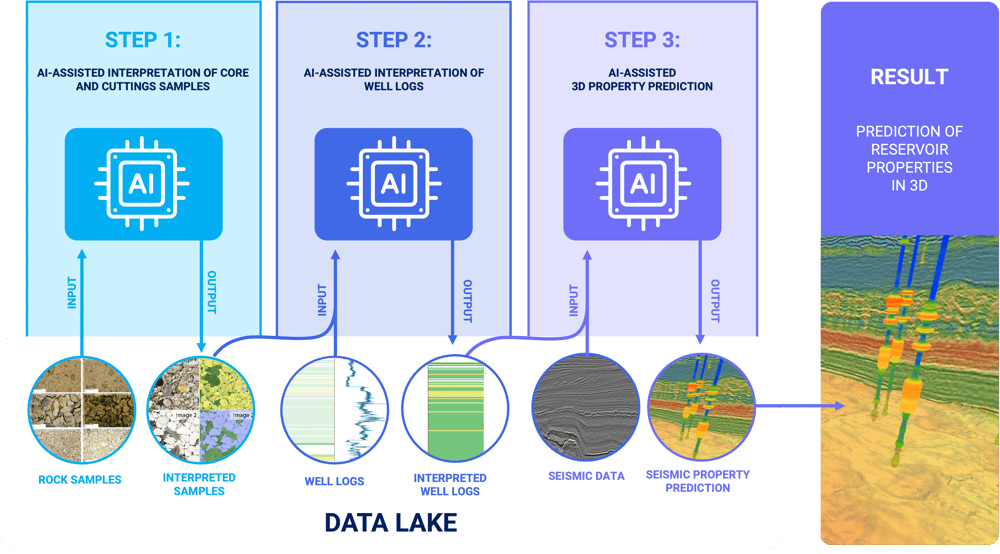
This multi-model AI workflow can be applied to classification and regression problems and contains three major phases corresponding to data sources at different scales:
- Phase 1: works on samples, including core images, cutting images, core-plug measurements, and cutting measurement (millimetre to centimetre scale).
- Phase 2: works on well logs, including composite wireline logs and computed petrophysical interpreted (CPI) logs (centimetre to metre scale).
- Phase 3: works on seismic data, including angle stack and velocity volumes (metre to kilometre scale)
Each of the steps in the workflow provides both a prediction and a quantification of the uncertainty surrounding that prediction. It is important to be able to quantify the uncertainty because we can never achieve 100 % certainty. By systematically assessing the uncertainty at each juncture and seamlessly integrating it into the subsequent steps, we gain a more comprehensive understanding of potential risks compared to traditional methods.
That is the opportunities of AI driven composite workflows and data integration. The emphasis here is on genuine integration, not just combination of data. A unique feature of this approach is its recursive nature; you can circle back, recalibrate, and refine. Imagine a printer sketching an image layer by layer, with each pass enriching the clarity and detail. Similarly, our predictions evolve and sharpen with every cycle.
Consider the intricate process of analysing rock samples, contextualising them based on their origin within a well, and then comparing this with seismic data. This merging not only aligns varying scales of data but also bridges the gap between diverse geoscience disciplines. It's a testament to how AI can turn isolated silos of knowledge into a cohesive, multidisciplinary narrative.
Examples of the workflow applied to data from the Norwegian Continental Shelf (NCS)
Let's have a look at how this workflow can be applied to an extensive dataset from the Norwegian Continental Shelf (NCS). In this study, we demonstrate how to leverage the data available for an entire basin to make data-driven predictions across scales, including the interpretation of rock samples, wireline logs, and the quantitative interpretation of 3D seismic data.
We used an extensive dataset from the NCS containing:
- 718 663 cuttings samples
- 77 008 metres of core
- 121 396 core plugs
- 1 501 kilometres of logs from 110 wells
- A seismic survey covering 44 969 km2
Phase 1: Lithology prediction from rock samples
The results from Phase 1 are illustrated in Figure 1 below, where we use multiple computer vision methods (image classification and image segmentation) and the XRF method to extract lithology from cutting samples. The first frame shows the prediction of image classification technique on cutting images, where each image is assigned to a single lithology category, such as sandstone, mudstone, and limestone. The confusion matrix measures the accuracy of predictions compared to the labels. Moving to the second frame, it details the classification results concerning sandstone types, be it cemented or loose, and breaks down grain sizes from fine to coarse. The third frame demonstrates the results of image segmentation. Here, original cutting images stand side-by-side with their respective lithology predictions, all complemented by a well plot that provides a visual guide to lithology distributions at varying depths. Lastly, the fourth frame illustrates how to create the lithology log based on the XRF data.

Figure 1: Illustration of phase 1 results at a single well, working on the samples, including core/cutting images and core/cutting measurements, to determine the lithology log.
Phase 2: Lithology prediction from well logs
In Phase 2, we train the ML models using different algorithms, including XGBoost (Chen & Guestrin, 2016), Random Forest (Ho, 1995), and Multilayer Perceptron (Rumelhart et al., 1985) with the QCed wireline composite logs as features and lithology logs from phase 1 as labels. Then, we apply the models to all the wells to obtain the AI-predicted lithology logs and compare them with each other. The ensemble confidence metric is used to measure the level of agreement between the predicted logs. Any sample with a low level of agreement is flagged, and all wells are ranked in terms of the percentage of flagged samples. We then try to understand why some wells have a low ranking, such as whether they contain some “out-of-distribution” data that has not been seen in other training data or has a feature-noise problem. Phase 2 is implemented iteratively until the performance metrics (e.g., ensemble confidence) reach the satisfaction criteria.
Figure 2 illustrates the workflow of phase 2, where we combine the predictions on the sample interpretation with the wireline logs and train the AI models to predict lithology and reservoir properties for multiple wells across a vast area. Figure 3 displays a subset of the results obtained from Phase 2. It shows the lithology log for the wells in Quad 30, 31 and 32, which were predicted from ML models using the sample interpretations as the labels and the wireline logs as the features.
Figure 2: Illustration of the phase 2 result using the predicted lithology log from phase 1 as the label and the wireline logs as features to train several AI models to predict lithology for multiple wells across the Norwegian Continental Shelf.
.jpg?width=4374&height=1884&name=Figure%203%20(1).jpg)
Figure 3: The cross-section (from West to East) of the wells in Quad 30, 31 and 32, with the lithology log resulting from ML models trained with the sample interpretations as labels and wireline logs as features. The selected wells are displayed are display in red on the mini-map.
Phase 3: Lithology prediction from seismic data
In phase 3, the predicted logs from phase 2 are used as labels, while the seismic data (angle stacks and velocity volumes) are used as features to train ML models to predict the reservoir properties as 3D volumes covering the vast area.
Figure 4 presents an Inline with a lithology prediction (Figure 4a) and sand percentage prediction (Figure 4b) from the ML models trained with the predicted logs from phase 2 and angle stacks within a cropped survey in Quad 31.
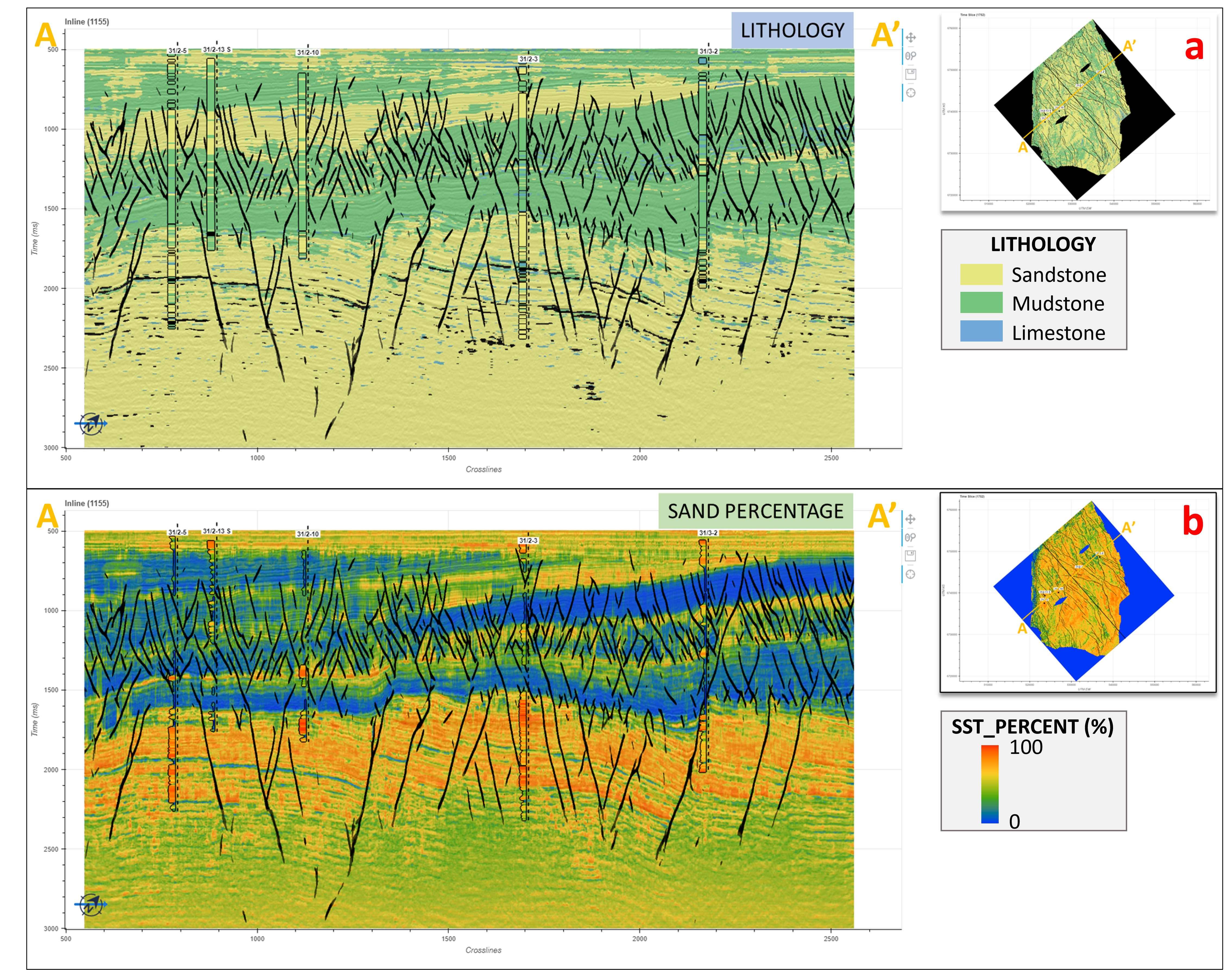
Figure 4: The volumes of lithology prediction (Figure 4a) and sand percentage prediction (Figure 4b) from ML models trained with the predicted logs from phase 2 as labels and seismic data (angle stacks and velocity volume) as features.
Here, we showcased a comprehensive study and a composite workflow to leverage the data available and make data-driven predictions across scales. We curated and integrated data and propagated the ground truth information from the sample level (core and cutting data) to the basin level (seismic data), aided by multiple machine learning methods and models. The value of the available ground truth information was maximised through an iterative, ensemble-based process of QC and data annotation.

